AI Crawlers Explained: GPTBot, ClaudeBot, PerplexityBot and How to Let Them In (2026)
A practical guide to what AI crawlers like GPTBot, ClaudeBot, and PerplexityBot do, how to identify them in your logs, and how to configure robots.txt to let them in so your content stays eligible for citation in AI-generated answers.

TL;DR
AI crawlers are bots that fetch your pages to power AI search and training. The three that matter most are OpenAI's GPTBot, Anthropic's ClaudeBot, and PerplexityBot — each named by a distinct user-agent in your logs. To be cited in AI answers, allow their search and user agents in robots.txt. Blocking them removes you from the fastest-growing discovery channel on the web.
What is an AI crawler?
An AI crawler is an automated bot that fetches public web pages so an AI system can train on them, index them for retrieval, or read them in real time to answer a user's question. AI crawlers visit websites to collect text, then feed it into model training, retrieval systems, or live answer generation. Contently
They behave like traditional search crawlers in one important way: each identifies itself with a distinct user-agent string and obeys robots.txt rules, so site owners can allow or block them selectively. Contently
The split that trips people up is purpose. A single AI company usually runs several bots — one for training, one for search indexing, one for fetching a page the moment a user asks about it. OpenAI runs a three-bot system: GPTBot for training, OAI-SearchBot for search indexing, and ChatGPT-User for user-initiated retrieval. Anthropic and Perplexity follow the same pattern. Blocking one does not block the others, which is the single most common configuration mistake — and one of the first things an AI visibility tool like Anagram will flag when it audits a site. ALM Corp
Why do AI crawlers matter in 2026?
They matter because AI answers are now a primary discovery channel, and a crawler that can't reach your page can't cite it. AI search visits grew 42.8% year over year, climbing from 15.6 billion to 27.4 billion between Q1 2025 and Q1 2026. Blocking the bots that feed those answers quietly removes a brand from that channel. Contently
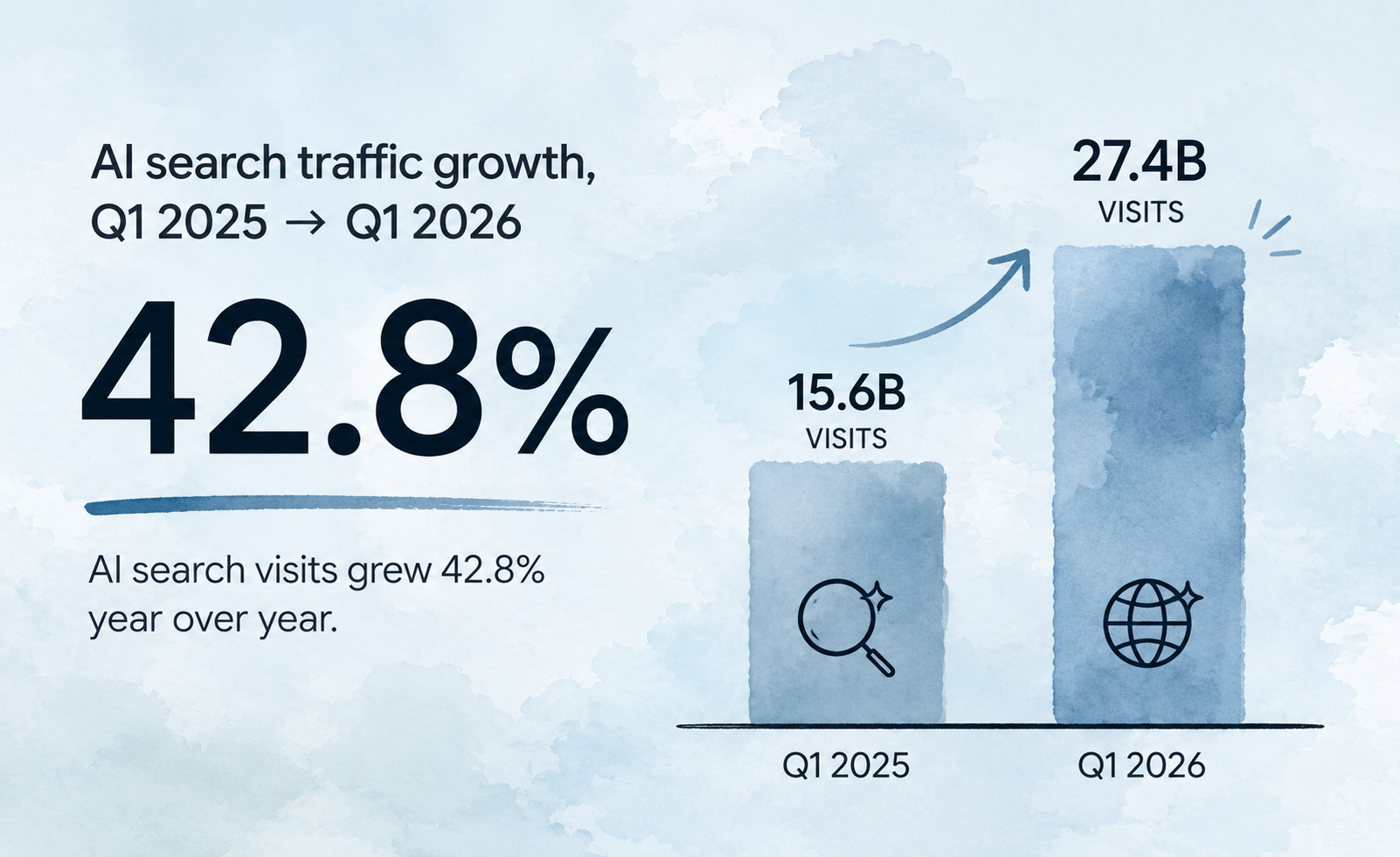
The traffic is concentrated. ChatGPT reached 700 million weekly active users by September 2025, and 87.4% of AI referral traffic originates from ChatGPT. Cutting off OpenAI's fetch agents closes the largest AI discovery channel available today. Contently
The growth rate is steep even off a small base. Digiday data showed ChatGPT referrals increasing 52% year-over-year from September to November 2025, while Gemini referral traffic grew 388% in the same period. The honest framing: AI referrals are still a fraction of traditional search, but the curve is the story. ALM Corp
What are GPTBot, ClaudeBot, and PerplexityBot — and how do they differ?
GPTBot (OpenAI), ClaudeBot (Anthropic), and PerplexityBot (Perplexity) are the three most active AI crawlers on the web, and once you see the pattern they share, all of them get easier to manage. Each vendor runs a small fleet split by job: a training bot that collects content for future models, a search bot that indexes pages for AI answers, and a user bot that fetches a page the instant someone asks about it.
The names differ, but the roles map cleanly across all three vendors:
Job | OpenAI | Anthropic | Perplexity |
|---|---|---|---|
Training — feeds future models |
|
| (uses third-party data) |
Search indexing — eligibility for AI answers |
|
|
|
User fetch — reads a page on request |
|
|
|
A few vendor-specific details are worth knowing once you've got the shared map in your head:
OpenAI split its bots apart. OpenAI separated GPTBot from its search-related bots in late 2024. The consequence of blocking the search bot is spelled out plainly: OpenAI's documentation tells publishers that sites blocking OAI-SearchBot will not appear in ChatGPT search answers, though navigational links may still appear. One caveat — OpenAI explicitly states that ChatGPT-User may not be governed by robots.txt in the same way as automated crawlers. ALM Corp + 2
Anthropic's three bots are strict about robots.txt — and fully independent. ClaudeBot handles model training, Claude-SearchBot handles search indexing, and Claude-User fetches pages at a user's direct request. Critically, blocking only ClaudeBot does not block Claude-SearchBot or Claude-User — each token needs its own directive. The bots are well-behaved by design: ClaudeBot, Claude-User, and Claude-SearchBot respect "do not crawl" signals by honoring industry-standard robots.txt directives and respect anti-circumvention technologies, stating they do not attempt to bypass CAPTCHAs. Siteline + 2
Perplexity is the one to watch. Its primary bot is built for retrieval, not training: when users ask Perplexity questions, PerplexityBot fetches and reads web pages to generate cited answers, so blocking it directly prevents your content from appearing in Perplexity's answers. Its user agent is contested — Perplexity has stated that Perplexity-User "is an agent, not a bot" and therefore is not required to honor robots.txt, a position that has caused real disputes with publishers and Cloudflare. And it has been caught going further: on August 4, 2025, Cloudflare published a report showing Perplexity using undeclared crawlers that rotate user-agents, IPs, and ASNs to evade no-crawl directives. For brands chasing visibility this is mostly academic — you want PerplexityBot in — but it shapes how you'd block it if you ever needed to. MarGen + 2
How do I let AI crawlers in? (robots.txt)
You let them in by adding an explicit Allow directive for each bot in your robots.txt file. Robots.txt is a plain-text file at a site's root that tells crawlers which paths they may access, and AI crawlers honor it the same way classic search bots do. The file lives at yourdomain.com/robots.txt, and changes take effect on the next crawl. Contently
The rule that matters most: listing crawlers individually beats a single wildcard rule, because it keeps full control over which AI engine sees which part of the site. Here's a welcome-mat configuration for the major AI engines: Contently
# OpenAI
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
# Anthropic
User-agent: ClaudeBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
# Perplexity
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /
# Google AI (does not affect Google Search ranking)
User-agent: Google-Extended
Allow: /If you want AI search visibility but not to feed model training, allow the search and user agents (OAI-SearchBot, Claude-SearchBot, PerplexityBot) and disallow the training agents (GPTBot, ClaudeBot, Google-Extended). Blocking Google-Extended prevents your content from being used to train Gemini models without affecting your regular Google search rankings, because Googlebot is a separate crawler. MarGen
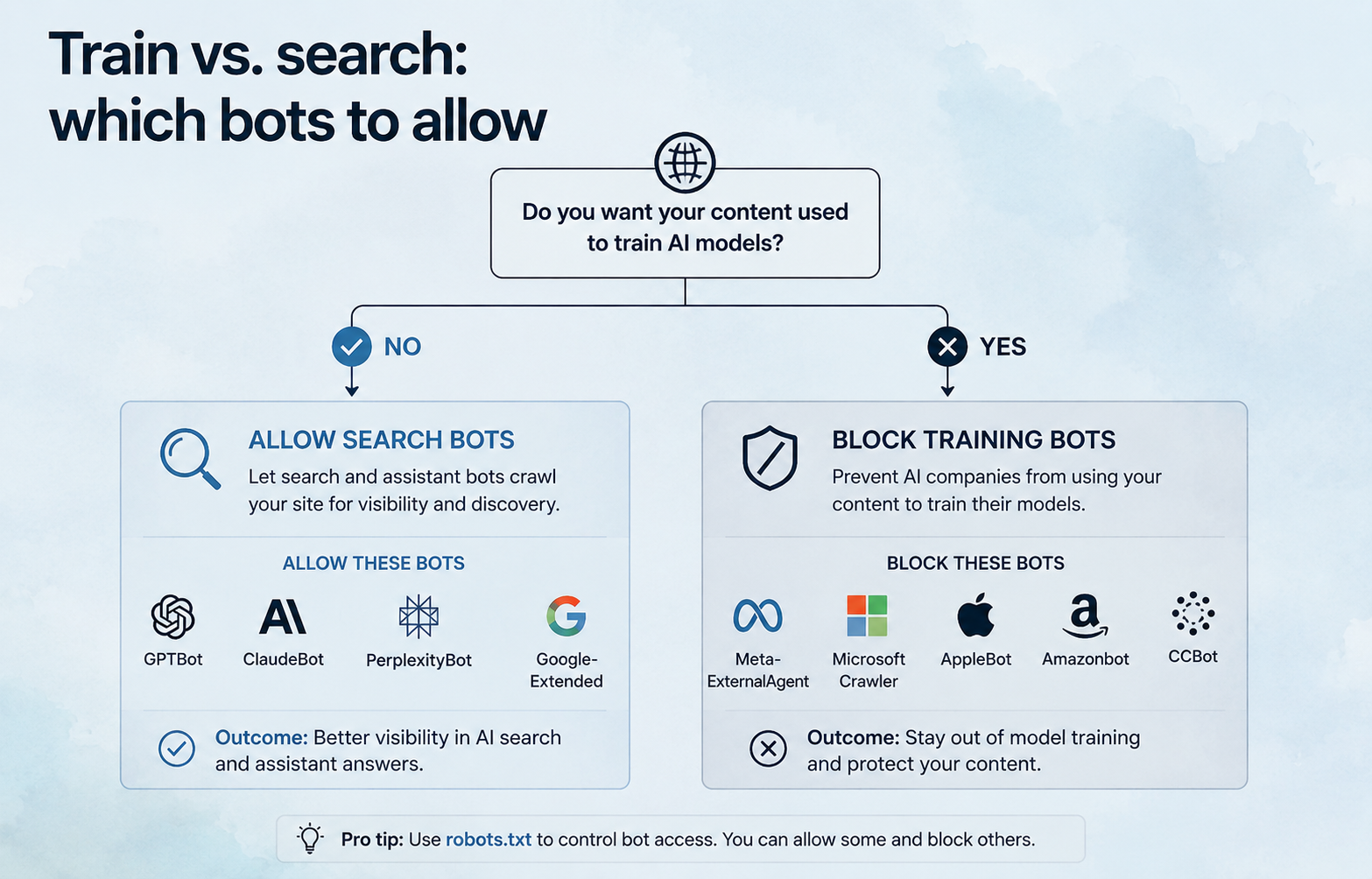
Should I block AI crawlers or allow them?
For most brands that want to be found, allow them — blocking is a deliberate trade-off, not a safe default. The decision hinges on training versus visibility. Blocking AI training crawlers like GPTBot, Google-Extended, and ClaudeBot prevents your content from being used in model training, which is a legitimate choice; blocking AI search and user agents like OAI-SearchBot, Claude-SearchBot, and PerplexityBot removes your content from eligibility for AI search citations and AI-generated answers. BrightEdge
The reasonable middle ground for a startup building AI visibility: allow everything, and keep a server-level rule ready in case a bot misbehaves. Bytespider and Perplexity's stealth crawlers have both been documented ignoring robots.txt, and for non-compliant bots the only real defense is at the server or WAF level. Soar Agency
How do I verify a crawler is real and not a spoof?
Verify it with a reverse DNS lookup, not by trusting the user-agent string alone — anyone can fake a header. To verify legitimate ClaudeBot traffic, perform a reverse DNS lookup; real ClaudeBot IPs resolve to anthropic.com domains, which protects you from spoofed requests. Dataprixa
One critical "don't": avoid blocking these bots by IP. IP-based blocking is unreliable because Anthropic uses public cloud-provider IPs, and blocking those IPs may also prevent the bot from reading your robots.txt. Control happens at the user-agent level for compliant bots, and at the WAF level for the ones that aren't. Siteline
AI crawler quick reference
Crawler | Operator | Primary job | Honors robots.txt? |
|---|---|---|---|
GPTBot | OpenAI | Training | Yes |
OAI-SearchBot | OpenAI | Search indexing | Yes |
ChatGPT-User | OpenAI | User fetch | Partially — OpenAI says not fully governed |
ClaudeBot | Anthropic | Training | Yes |
Claude-SearchBot | Anthropic | Search indexing | Yes |
Claude-User | Anthropic | User fetch | Yes |
PerplexityBot | Perplexity | Search retrieval | Yes |
Perplexity-User | Perplexity | User fetch | Disputed — Perplexity says no |
Google-Extended | AI training | Yes |
How do I know if I'm already blocking AI crawlers?
Start by reading your own robots.txt at yourdomain.com/robots.txt and checking for a blanket Disallow: / under User-agent: *, which silently catches every bot you didn't explicitly allow. Then check your server logs for the user-agent tokens in the table above — if you never see OAI-SearchBot or Claude-SearchBot, you may be invisible to those engines.
The harder question isn't whether a crawler can reach you — it's whether reaching you is translating into citations. That's the gap AI visibility platforms close. Anagram monitors how often and how prominently a brand is cited across ChatGPT, Perplexity, and Gemini, then traces low visibility back to its cause — sometimes a blocked search bot, more often a content gap where you simply haven't published the answer the engine wants to quote. Crawler access is the thing you check first; citation tracking is how you learn what to fix next.
How does this fit into a GEO strategy?
Letting crawlers in is necessary but not sufficient — it's the floor, not the ceiling. A bot that can reach your page still has to find content worth citing. Crawler access gets you eligible; structure, original data, and clear answers get you cited.
This is the half of the work that compounds. To maximize visibility in generative AI engines, it's essential to ensure important sections and editorial pages are accessible to crawlers — and then to know which prompts you're actually surfacing for, and which competitors are taking the citations you want. This is the loop Anagram is built around: it ingests your brand deeply, tracks your share of citations against the specific prompts your buyers ask, and surfaces the content gaps to close so that each fix measurably moves your visibility. Opening your robots.txt is step zero. Knowing what to write next — and proving it worked — is the part that turns access into answers. Botrank
Frequently asked questions
Does blocking GPTBot hurt my Google rankings? No. GPTBot is OpenAI's crawler and has nothing to do with Googlebot. Similarly, blocking Google-Extended affects only Gemini training, not Google Search rankings.
If I allow ClaudeBot, am I also allowing Claude search and user fetches? No. Each Anthropic bot needs its own directive. Allowing ClaudeBot does nothing for Claude-SearchBot or Claude-User — list all three.
Will allowing these crawlers slow down my site? It can add load, since crawler traffic consumes bandwidth and CPU. Most compliant AI bots rate-limit themselves and respect Crawl-delay, but large sites should monitor logs for aggressive fetching.
Can I allow AI search but block AI training? Yes. Allow the search/user agents (OAI-SearchBot, Claude-SearchBot, PerplexityBot) and disallow the training agents (GPTBot, ClaudeBot, Google-Extended).
How do I track whether AI engines are actually citing me? Server logs tell you a crawler visited; they don't tell you whether you were cited in an answer. A visibility tool like Anagram tracks citations and prominence across ChatGPT, Perplexity, and Gemini so you can see whether opening crawler access is paying off.
Sources
Contently — AI Crawlers Explained: GPTBot, ClaudeBot, and PerplexityBot (2026)
ALM Corp — Anthropic's Three-Bot Framework and Your robots.txt Strategy (2026)
Soar — AI Bots robots.txt Guide: GPTBot, ClaudeBot, PerplexityBot (2026)
BrightEdge — Guide for AI Agents (2026)
MarGen — Robots.txt and AI Crawlers: Block or Allow? (2026)
Search Engine Roundtable — Anthropic Updates Its Crawler Documentation (2026)
Siteline — Claude-SearchBot AI Agent Directory (2026)
MIT AI Agent Index — Claude (2025)